递归的执行过程
这个问题困惑了我好久,从当初学习计算机开始就没有弄明白这个过程,只听说过能用迭代取代递归的地方就用迭代,因为递归很容易引起内存泄露。不过,作为一名专业的程序员,了解这些东西都是必不可少的,所以我今天就把它记录下来。 我们拿一个简单的程序来作为例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
我们可以看到,compute函数里面实现了递归,当n==1的时候就返回。这是每一个递归函数的必要条件,那么函数在return之后又会做些什么呢?其实过程是这样的,如果执行compute(5),首先判断n是否等于1,如果不是,就计算5 * compute(4),再次判断n是否等于1,如果不等就继续执行4*compute(3)。这样执行下去直到n==1。这时,所有函数的递归调用可以看成一个顺序执行的函数,这个函数类似于:5 * compute(4) = 5 * (4 * compute(3)) = 5 * (4 * (3 * compute(2))) = 5 * (4 * (3 * (2 * compute(1)))),当compute(1)的值知道的时候, 就开始返回了。
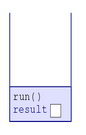
同时我们应该知道的是,方法的调用其实是入栈与出栈。所以,我们可以通过下面这些图来了解执行过程。 1.To start off the program, the program pushes a frame corresponding to an invocation to run(). Notice how this frame includes room for run’s variable result.
2.When the computer sees that run() invokes compute(4), the computer places a new frame atop the stack corresponding to compute; this frame will include the variable n, whose value is initially 4.

3.When the computer sees that compute(4) invokes compute(3), the computer places a new frame atop the stack, containing the variable n, whose value is initially 3.

4.When the computer sees that compute(3) invokes compute(2), the computer places a new frame atop the stack, containing the variable n, whose value is initially 2.
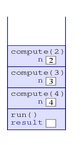
5.When the computer sees that compute(2) invokes compute(1), the computer places a new frame atop the stack, containing the variable n, whose value is initially 1.

6.When the computer sees that compute(1) returns, it pops the top frame off the stack and resumes with whatever frame is now at the top — which happens to be the frame for compute(2).

7.When the computer sees that compute(2) returns, it pops the top frame off the stack and resumes with compute(3).

8.When the computer sees that compute(3) returns, it pops the top frame off the stack and resumes with compute(4).
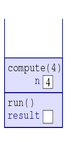
9.When the computer sees that compute(4) returns, it pops the top frame off the stack and resumes with run(). The run() invocation assigns the valued returned to its result variable, which modifies the variable in its frame.
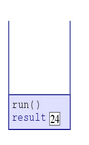
10.As the computer executes the method atop the stack, run, it sees that the method invokes print. It thus pushes print(24) onto the stack. In fact, printwill push additional methods onto the stack, which are all eventually popped off.

11.Once print returns, the computer pops its frame off the stack and continues executing run. In fact, run will return promptly (since there is nothing else to do in that method). Thus, its frame will be popped off, too. Once the stack is empty, the computer halts execution of the program.

上面谈到的递归是一种比较简单的实现,下面我们来探讨一下难度稍大的递归,程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
使用+连接字符串每次都生成新的对象,而且是在堆内存上进行,而堆内存速度比较慢(相对而言),那么再大量连接字符串时直接+是不可取的,当然需要一种效率高的方法。Java提供的StringBuffer和StringBuilder就是解决这个问题的。区别是前者是线程安全的而后者是非线程安全的,StringBuilder在JDK1.5之后才有。不保证安全的StringBuilder有比StringBuffer更高的效率。
在fibonacci这个方法里面,它两次调用了自己,那么它的执行顺序是怎么样的呢?其实这样的一次执行更像是一次二叉树的前序遍历。它会首先执行前面那个方法,即fibonacci(number - 1),当这个方法返回后再执行fibonacci() 如果执行fibonacci(5),它的执行过程会是下面这个样子的:
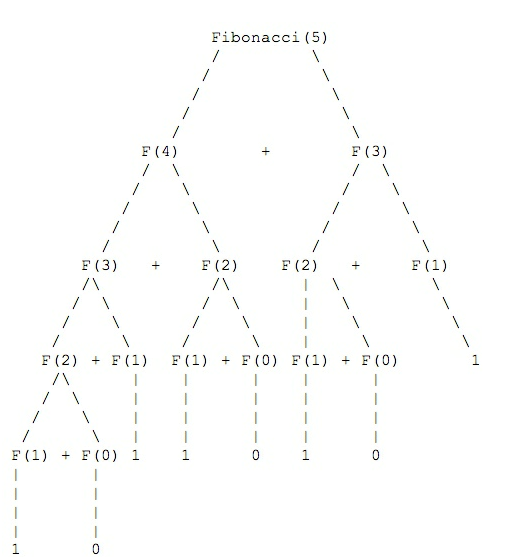
所以,fibonacci(5)的执行顺序会是首先到最左下角F(1),然后回到F(2),然后再到F(0),这样F(2)就执行完毕了。接下来是F(3)的执行,因为F(2)已经得出结果了那么就只需要算F(1)。然后回到F(3),来到F(4)。F(4)的右子树没有被遍历,所以这次会使用相同的方法计算出F(2)。这样F(4)的结果就算出来了。然后回到顶点,开始算顶点右边那个节点F(3)。方法同Fibonacci(5)左边的遍历方法相同。这样就完成了一次递归的计算。