理解Java中的重排序
重排序通常是编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段。重排序分为两类:编译期重排序和运行期重排序,分别对应编译时和运行时环境。
在并发程序中,程序员会特别关注不同进程或线程之间的数据同步,特别是多个线程同时修改同一变量时,必须采取可靠的同步或其它措施保障数据被正确地修改,这里的一条重要原则是:不要假设指令执行的顺序,你无法预知不同线程之间的指令会以何种顺序执行。
但是在单线程程序中,通常我们容易假设指令是顺序执行的,否则可以想象程序会发生什么可怕的变化。理想的模型是:各种指令执行的顺序是唯一且有序的,这个顺序就是它们被编写在代码中的顺序,与处理器或其它因素无关,这种模型被称作顺序一致性模型,也是基于冯·诺依曼体系的模型。当然,这种假设本身是合理的,在实践中也鲜有异常发生,但事实上,没有哪个现代多处理器架构会采用这种模型,因为它是在是太低效了。而在编译优化和CPU流水线中,几乎都涉及到指令重排序。
一、编译期重排序
编译期重排序的典型就是通过调整指令顺序,在不改变程序语义的前提下,尽可能减少寄存器的读取、存储次数,充分复用寄存器的存储值。
假设第一条指令计算一个值赋给变量A并存放在寄存器中,第二条指令与A无关但需要占用寄存器(假设它将占用A所在的那个寄存器),第三条指令使用A的值且与第二条指令无关。那么如果按照顺序一致性模型,A在第一条指令执行过后被放入寄存器,在第二条指令执行时A不再存在,第三条指令执行时A重新被读入寄存器,而这个过程中,A的值没有发生变化。通常编译器都会交换第二和第三条指令的位置,这样第一条指令结束时A存在于寄存器中,接下来可以直接从寄存器中读取A的值,降低了重复读取的开销。
1、数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
名称 代码示例 说明 写后读 a = 1;b = a; 写一个变量之后,再读这个位置。 写后写 a = 1;a = 2; 写一个变量之后,再写这个变量。 读后写 a = b;b = 1; 读一个变量之后,再写这个变量。 上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
前面提到过,编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
2、as-if-serial语义
as-if-serial语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例:
1 2 3 | |
上面三个操作的数据依赖关系如下图所示:
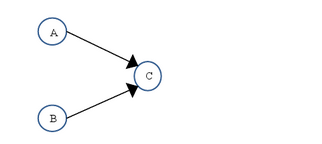
如上图所示,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。下图是该程序的两种执行顺序:
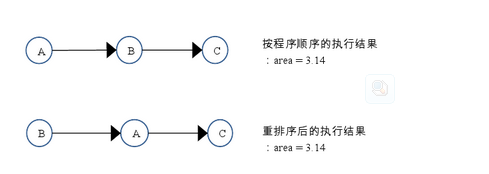
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
程序顺序规则
根据happens- before的程序顺序规则,上面计算圆的面积的示例代码存在三个happens- before关系:
A happens- before B; B happens- before C; A happens- before C; 这里的第3个happens- before关系,是根据happens- before的传递性推导出来的。
这里A happens- before B,但实际执行时B却可以排在A之前执行(看上面的重排序后的执行顺序)。在第一章提到过,如果A happens- before B,JMM并不要求A一定要在B之前执行。JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见;而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens- before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法(not illegal),JMM允许这种重排序。
在计算机中,软件技术和硬件技术有一个共同的目标:在不改变程序执行结果的前提下,尽可能的开发并行度。编译器和处理器遵从这一目标,从happens- before的定义我们可以看出,JMM同样遵从这一目标。
重排序对多线程的影响
现在让我们来看看,重排序是否会改变多线程程序的执行结果。请看下面的示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
flag变量是个标记,用来标识变量a是否已被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作1和操作2重排序时,可能会产生什么效果?请看下面的程序执行时序图:
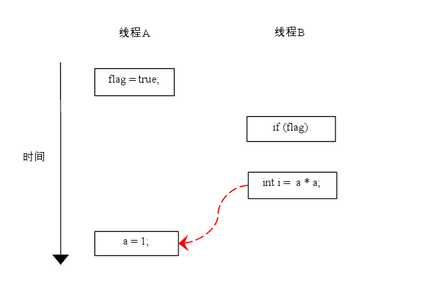
如上图所示,操作1和操作2做了重排序。程序执行时,线程A首先写标记变量flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时,变量a还根本没有被线程A写入,在这里多线程程序的语义被重排序破坏了!
※注:本文统一用红色的虚箭线表示错误的读操作,用绿色的虚箭线表示正确的读操作。
下面再让我们看看,当操作3和操作4重排序时会产生什么效果(借助这个重排序,可以顺便说明控制依赖性)。下面是操作3和操作4重排序后,程序的执行时序图:
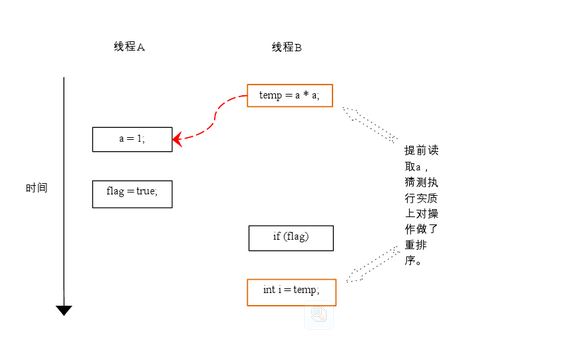
在程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(reorder buffer ROB)的硬件缓存中。当接下来操作3的条件判断为真时,就把该计算结果写入变量i中。
从图中我们可以看出,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义!
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
二、确保顺序性
尽管指令在执行时并不一定按照我们所编写的顺序执行,但毋庸置疑的是,在单线程环境下,指令执行的最终效果应当与其在顺序执行下的效果一致,否则这种优化便会失去意义。
通常无论是在编译期还是运行期进行的指令重排序,都会满足上面的原则。
三、Java存储模型中的重排序
在Java存储模型(Java Memory Model, JMM)中,重排序是十分重要的一节,特别是在并发编程中。JMM通过happens-before法则保证顺序执行语义,如果想要让执行操作B的线程观察到执行操作A的线程的结果,那么A和B就必须满足happens-before原则,否则,JVM可以对它们进行任意排序以提高程序性能。
volatile关键字可以保证变量的可见性,因为对volatile的操作都在Main Memory中,而Main Memory是被所有线程所共享的,这里的代价就是牺牲了性能,无法利用寄存器或Cache,因为它们都不是全局的,无法保证可见性,可能产生脏读。
volatile还有一个作用就是局部阻止重排序的发生,对volatile变量的操作指令都不会被重排序,因为如果重排序,又可能产生可见性问题。
在保证可见性方面,锁(包括显式锁、对象锁)以及对原子变量的读写都可以确保变量的可见性。但是实现方式略有不同,例如同步锁保证得到锁时从内存里重新读入数据刷新缓存,释放锁时将数据写回内存以保数据可见,而volatile变量干脆都是读写内存。
原帖地址 :