正则表达式必知必会 2
重复匹配
匹配一个或多个字符
+: 匹配一个或多个字符(不匹配零个字符的情况).
#
文本: Send personal email to ben@forta.com. For questions about the book use support@forta.com. Feel free to send unsolicited email to spam@forta.com.
正则表达式: \w+@\w+.\w+
结果: ben@forta.com support@forta.com spam@forta.com
*: 匹配零个或多个字符.
?: 匹配零个或一个字符.
#
文本: The URL is http://www.forta.com, to connect securely use https://www.forta.com.
正则表达式: https?://[\w./]+
结果: http://www.forta.com https://www.forta.com
这里在s后面加了?,表示s既可以出现一次也可以不出现.
匹配的重复次数
重复次数 (interval): 精确定义+,*等元字符代表的字符的重复个数.这个个数定义在{}之间.
#
匹配RGB值(RGB值是由6个连续的任意字符或者0-9间的数字构成)
文本: \
正则表达式: #[a-zA-Z0-9][a-zA-Z0-9][a-zA-Z0-9][a-zA-Z0-9][a-zA-Z0-9][a-zA-Z0-9]
结果: #336655, #FFFFFF
修改后:
#
匹配RGB值(RGB值是由6个连续的任意字符或者0-9间的数字构成)
文本: \
正则表达式: #[a-zA-Z0-9]{6}
结果: #336655, #FFFFFF
上面的正则表达式规定{6}之前的字符连续出现6次.###为重复次数设定一个区间###
#
文本: 4/8/03 10-6-2004 2/2/2 01-01-01
正则表达式: \d{1,2}/[-\/]d{1,2}[-\/]\d{2,4}
结果: 3/8/03 10-6-2004 01-01-01
上面在\d后面跟上了这个字符具体出现的次数区间,两边都是inclusive.###匹配"至少重复多少次"###
#
文本:
1001: $489.02
1002: $42.33
1003: $1003.21
1004: $104.55
1005: $21.21
正则表达式: \d+: \$\d{3,}.\d{2}
结果: 1001: $489.02 1003: $1003.21 1004: $104.55
上面的正则表达式中\d{3,}表示至少出现3次数字,换句话说就是找金额大于100美元的匹配.
防止过度匹配
#
文本: This offer is not available for customers living in DC and MO
正则表达式: <[Bb]>.*<[Bb]>
结果: DC and MO
这样的结果显然不是我们预期的,这时因为.*属于贪婪型匹配,它们进行匹配的模式是多多益善而不是适可而止.它们会尽可能从一段文本的开头一直匹配到这段文本的结尾,而不是从这段文本的开头碰到第一个匹配为止.
为了达到我们想要的效果,我们需要使用元字符的懒惰型版本,这个版本与贪婪型正好相反.懒惰型版本的写法很简单,只需要在后面加上?后缀即可.
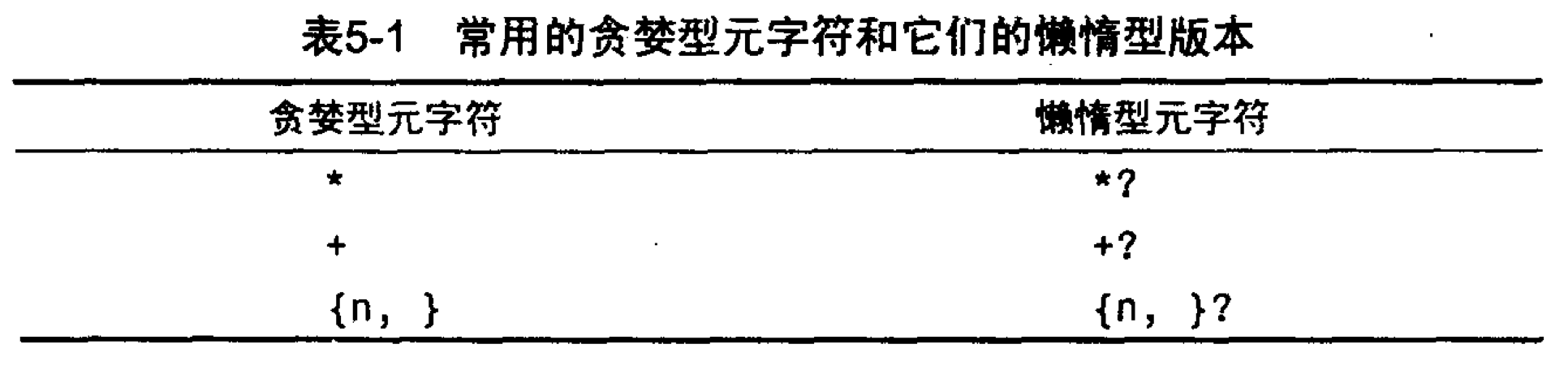
所以,我们可以使用懒惰型字符匹配来解决上面的问题.
#
文本: This offer is not available for customers living in DC and MO
正则表达式: <[Bb]>.*?<[Bb]>
结果: DC MO
位置匹配
位置匹配用来解决在什么地方进行字符串匹配操作的问题.
#
文本: The cat scattered his food all over the room.
正则表达式: cat
结果: The cat scattered his food all over the room.
这里的cat把一句话中的所有cat都找了出来,无论匹配的字符是单独的还是单词的一部分.
解决这个问题的办法只有一个:使用边界限定符,也就是在正则表达式里用一些特殊的元字符来表明我们想要匹配操作在什么位置发生.
单词边界
\b: 匹配单词的开始或结尾.
#
文本: The cat scattered his food all over the room.
正则表达式: \bcat\b
结果: The cat scattered his food all over the room.
单词cat的前后都有一个空格,空格是用来分割单词的字符之一.而单词scattered中的cat不能与之匹配,因为scattered中的cat前一个字符是s后一个字符是t,都不能与\b匹配.
\b中的b是boundary的意思,它匹配这样一个位置,这个位置位于一个能用来构成单词的字符(字母数字和下划线, 即\w)和不能构成单词的字符(即\W)之间.
值得注意的是如果想要匹配一个完整的单词,就需要在前后都加上\b.
#
文本: The captain wear his cap and cape proudly as he sat and listening to the recap of how his crew saved a men from a capsized vessel.
正则表达式: \bcap
结果: The captain wear his cap and cape proudly as he sat and listening to the recap of how his crew saved a men from a capsized vessel.
这里的正则表达式匹配以cap开头的任意单词.
#
文本: The captain wear his cap and cape proudly as he sat and listening to the recap of how his crew saved a men from a capsized vessel.
正则表达式: cap\b
结果: The captain wear his cap and cape proudly as he sat and listening to the recap of how his crew saved a men from a capsized vessel.
这里的正则表达式匹配以cap结尾的任意单词.
如果想要表面不匹配单词边界,可以使用\B.
#
文本: Please enter the nine-digit id as it appeared on your color - coded pass-key.
正则表达式: \B-\B
结果: color - coded
\B-\B匹配前后都不是单词边界的连字符.
字符串边界
^: 匹配字符串开头.
$: 匹配字符串结尾.
note: ^是一个多用途的元字符.当它在[]之间并且紧跟在[之后的时候,它表示取非.如果在字符集合的外面并在一个模式开头的时候,它将匹配字符串的开头.
#
文本:
1 2 3 4 5 | |
正则表达式: \<\?xml .* \?>
结果: \<?xml version=“1.0” encoding=“UTF-8” ?>
一个合法的XML文档都需要以文本的第一行作为开始,这里我想用这个正则表达式来匹配这个XML的头行,这里似乎奏效,但是其实不然.因为即使我在第一行前面加上一些支付,这个匹配也能成功.
#
文本:
1 2 3 4 5 6 | |
正则表达式: \<\?xml .* \?>
结果: \<?xml version=“1.0” encoding=“UTF-8” ?>
但显然这不是我想要的结果,因为头文件不在第一行,表示这不是一个合法的XML文件.
#
文本:
1 2 3 4 5 | |
正则表达式: ^\s \<\?xml . \?>
结果: \<?xml version=“1.0” encoding=“UTF-8” ?>
这一次对了,^\s*表示在文本的开头能有空格(包括回车,换行等), 但不能以其他的字符开头.
#
文本: \haha\
正则表达式: \</[Hh][Tt][Mm][Ll]>\s$
匹配: \
这里的正则表达式以\s$结尾,表示能有空格,但不能有其他字符.
分行匹配模式
?m: 分行匹配模式将把行分割符当作一个字符串分隔符来对待.在分行匹配模式下,^不仅匹配字符串的开头,还匹配分隔符(换行符)后面开始的位置.$不仅匹配字符串的结束,还匹配分隔符(换行符)后面的结束位置.在使用分行匹配模式的时候,?m必须出现在正则表达式的最前面.
#
文本:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
正则表达式: ?m^\s//.$
结果: // make sure not empty // init // Done
^\s*//.*$匹配一个字符串的开始,然后是任意多的空白字符,然后是//.再往后是任意文本,最后是字符串的结束.不过因为*是贪婪型字符,它将匹配第一条注释开始直到文本的结尾.加上?m之后,?m^\s*//.*$将把换行符作为一个字符串分隔符,这样就可以把每一行注释匹配出来了.