正则表达式必知必会 4
前后查找
#
文本:
1 2 3 | |
正则表达式: \<[Tt][Ii][Tt][Ll][Ee]>.*?\</[Tt][Ii][Tt][Ll][Ee]>
结果: \
本意是想要匹配出标题里面的文字,但是结果确实连标题的tag也一起匹配出来了,尽管我们可以使用上一章讲到的子表达式来把正则表达式分成3块然后取第2块出来,但是这样不免有些麻烦,这个时候就可以使用前后查找来解决这个问题.
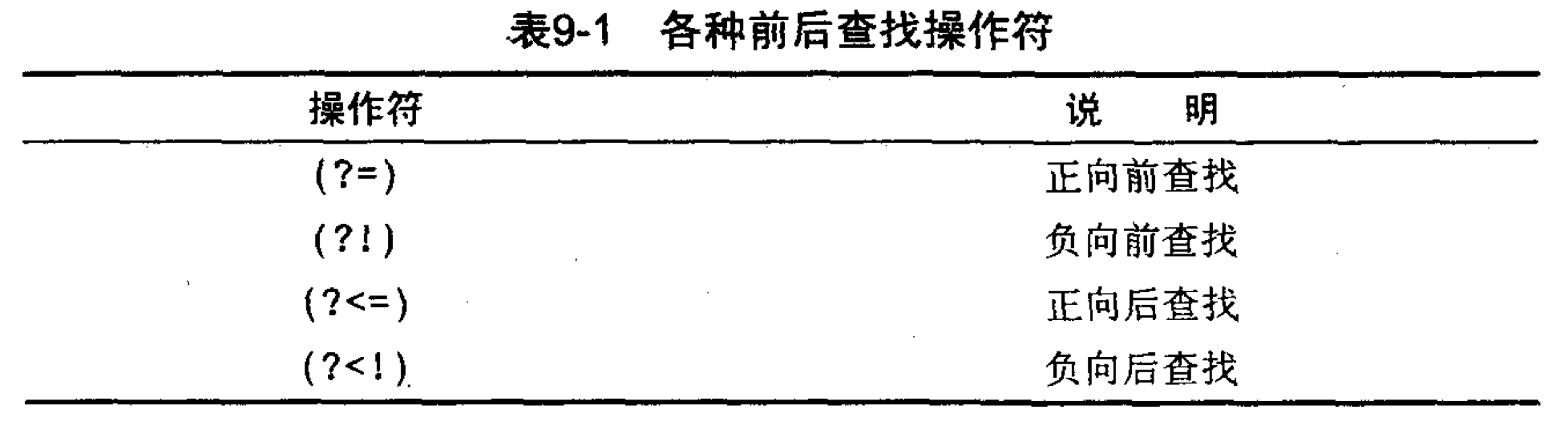
向前查找(?=): 指定一个必须匹配但无需在结果中返回的模式.从语法上看,向前查找就是一个以?=开头的子表达式,需要匹配的文本跟在=后面.
#
文本:
正则表达式: .+(?=:)
结果: http https ftp
上面列出的URL地址里,协议和主机名以冒号:相隔.模式.+匹配任意文本,子表达式(?=:)匹配冒号:.值得注意的是被匹配到的:并没有出现在结果中,我们用?=向正则表达式引擎说明只要找到:就行了,不要把它包含在最终的结果里.
#
文本:
正则表达式: .+(:)
这里的正则表达式没有使用向前查找,在最终的结果里面则包含了冒号.
向后查找
向后查找(?<=): 与向前查找大同小异.只是这次匹配但不返回的字符在首部了,它必须用在一个子表达式里.
#
文本:
ABC01: $23.12
HGG42: $122.81
AIOS98: $981.02
HSW92: $72.33
正则表达式: \$[\d.]+
结果: $23.12 $122.81 $981.02 $72.33
本想要匹配具体的金额,但是连同$也被返回了,这里就是向后匹配大显身手的时候.
#
文本:
ABC01: $23.12
HGG42: $122.81
AIOS98: $981.02
HSW92: $72.33
正则表达式: (?<=\$)[\d.]+
结果: 23.12 122.81 981.02 72.33
把向前和向后查找结合起来
#
文本:
1 2 3 | |
正则表达式: (?<=\<[Tt][Ii][Tt][Ll][Ee]>).*?(?=\</[Tt][Ii][Tt][Ll][Ee]>)
结果: Ben Forta’s Homepage
这里我们在两个tag之前分别使用了向后和向前查找,表明匹配两个tag,但不返回它们,所以最后的结果就只包含字符.
对前后查找取非
我们前面遇到的向前查找和向后查找都是使用某个特殊字符来定位然后向前或者向后匹配,这种查找称为正向前查找(positive lookahead)和正向后查找(positive lookbehind).下面讲到的内容与之正好想法,称为负向前查找(negative lookahead)和负向后查找(negative lookbehind),顾名思义我们可以猜到它们其实就是匹配不以某个字符开头或者结尾的模式.
#
文本: I paid $30 for 100 apples, 50 oranges and 30 pears. I saved $5 on this order.
正则表达式: (?<=\$)\d+
结果: 30 5
结果返回了以$开头的数字,既钱数. 接下来,如果我们只想查找水果个数.
#
文本: I paid $30 for 100 apples, 50 oranges and 30 pears. I saved $5 on this order.
正则表达式: \b(?<!\$)\d+\b
结果: 100 50 30
最后的结果只包含那些不以$开头的数字.值得注意的是我在这个正则表达式里面使用了分隔符\b,如果不使用这个,$30中的0也会被匹配.